
PageExtract
NarzędziaTekst, obrazy, czcionki i kod źródłowy
Rozłóż dowolną stronę internetową — wyodrębnij tekst, obrazy, czcionki, CSS, JavaScript, linki i metadane. Zapisz w bibliotece, przetwarzaj adresy URL partiami. Na urządzeniu, prywatnie, bez przesyłania.
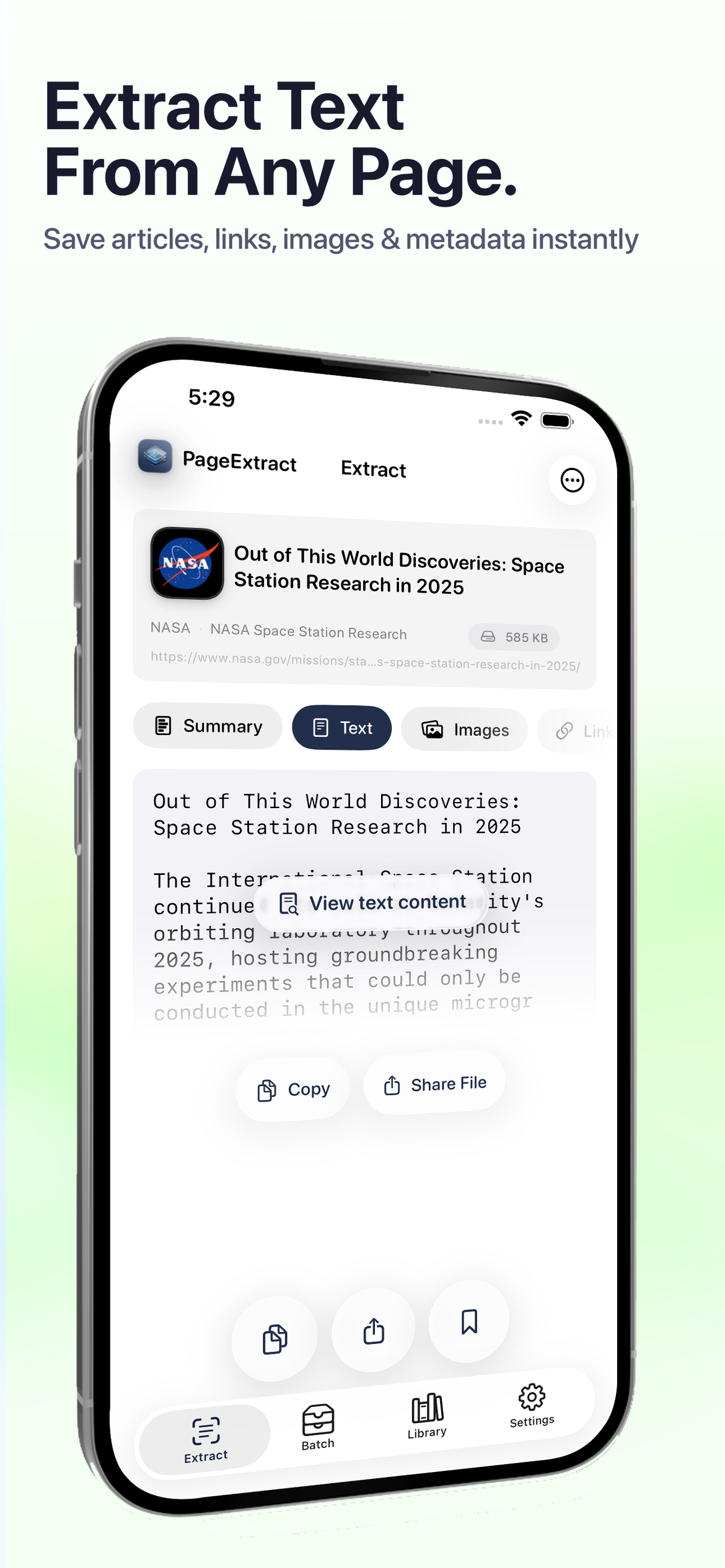
Wyodrębnij tekst z dowolnej strony
Uzyskaj czysty, czytelny tekst artykułu bez reklam i bałaganu. Skopiuj do schowka lub udostępnij jako zwykły tekst, Markdown lub PDF jednym dotknięciem.
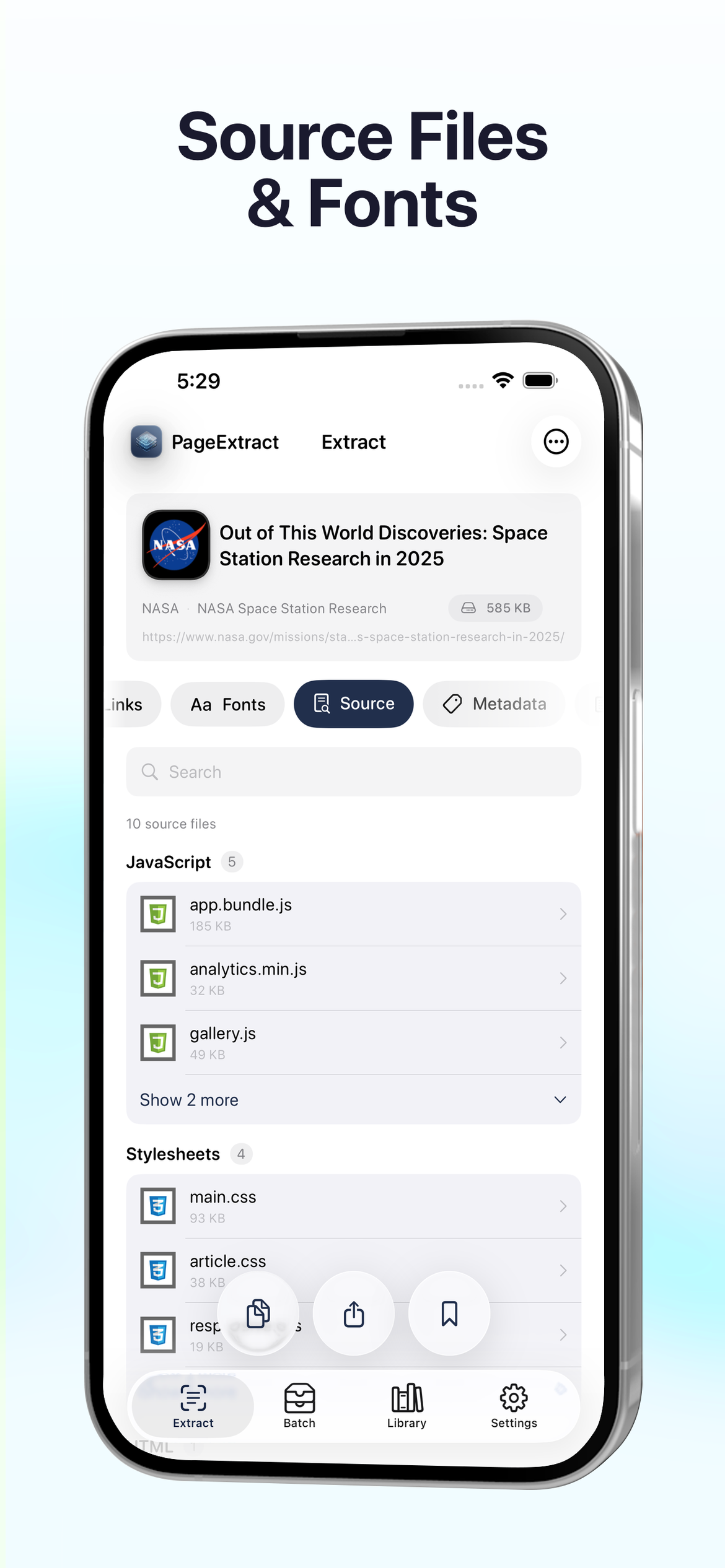
Zbadaj pliki źródłowe i czcionki
Zobacz każdy plik JavaScript, CSS i czcionek ładowany przez stronę. Sprawdź rozmiary plików, zagłęb się w poszczególne pliki i zrozum dokładnie, co napędza dowolną stronę.
Przeglądaj surowy kod źródłowy
Przeglądaj JavaScript i CSS z podświetlaniem składni i numerami linii. Zminimalizowane pliki są automatycznie formatowane, abyś mógł czytać i rozumieć kod dowolnej strony.
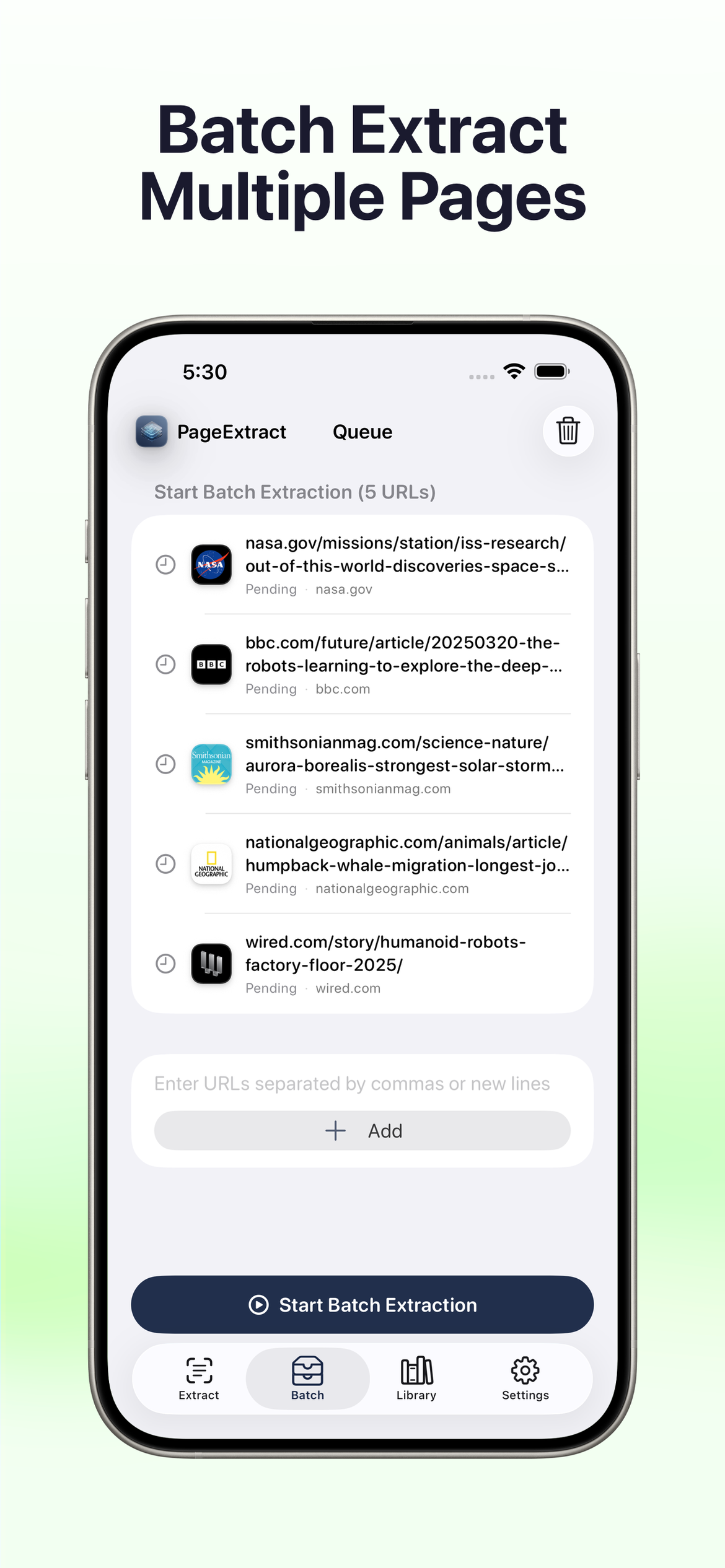
Wyodrębnij wiele stron jednocześnie
Dodaj wiele adresów URL do kolejki i wyodrębnij je wszystkie naraz. Idealne do badań, audytów stron, archiwizacji treści lub migracji treści między platformami.
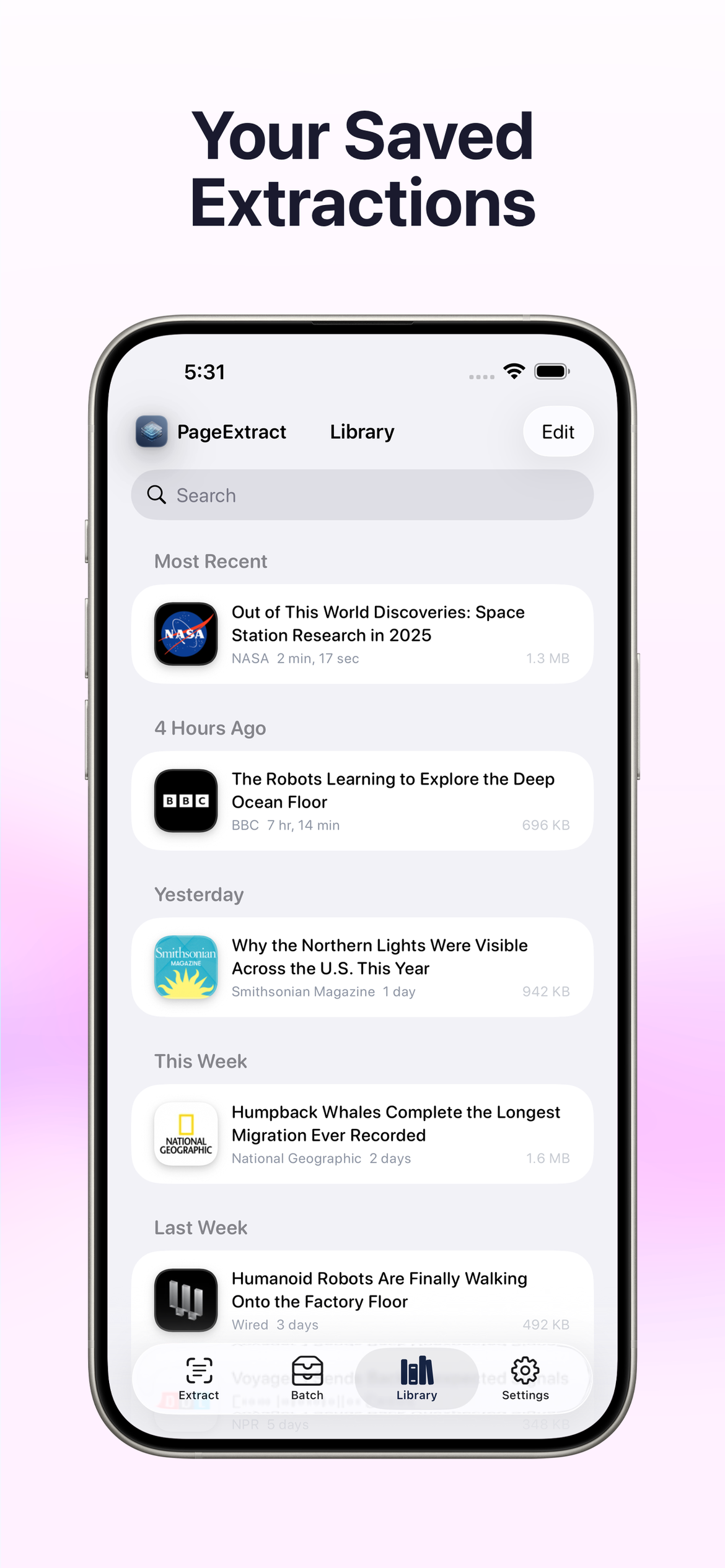
Twoje zapisane ekstrakcje
Zbuduj przeszukiwalną bibliotekę każdej wyodrębnionej strony. Każdy wpis zachowuje pełny artykuł, obrazy, linki, czcionki, metadane i pliki źródłowe do dostępu offline.
Synchronizacja iCloud i kontrola prywatności
Synchronizuj swoją bibliotekę na wszystkich urządzeniach dzięki iCloud. Zablokuj aplikację za pomocą Face ID lub Touch ID. Całe wyodrębnianie odbywa się na urządzeniu — bez przesyłania na serwer, bez śledzenia.

Głęboka analiza treści
Uzyskaj pełne podsumowanie dowolnej strony w jednym rzucie oka — rozmiar tekstu, liczba obrazów, czcionki, pliki źródłowe, metadane, linki, liczba słów i całkowity rozmiar danych na jednym panelu.
